Enterprise Mining Farm Management System
Mission-critical control plane managing 10,000+ ASIC crypto miners across multiple data centers, with real-time energy arbitrage against NordPool spot prices.
Bilttek
12 months
Lead Full Stack Engineer
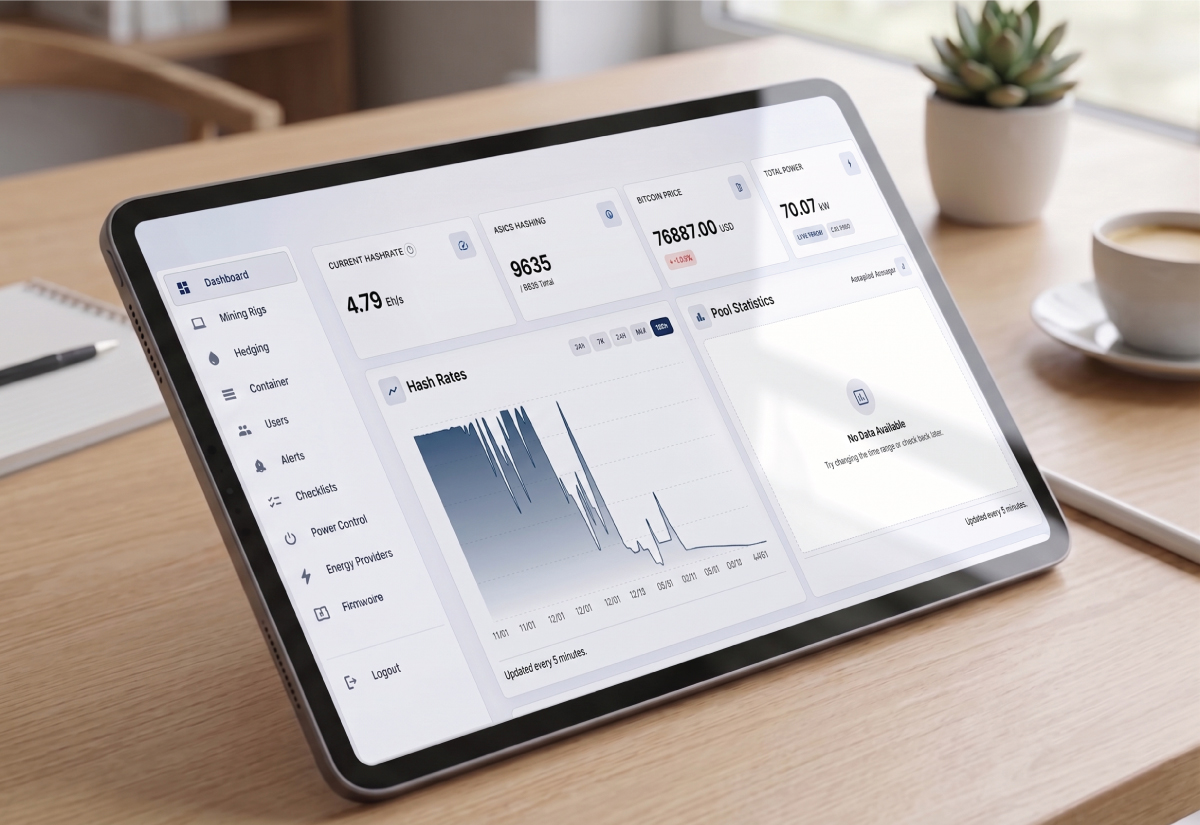
Managing 10,000+ Devices at Industrial Scale
Bilttek operates one of Europe's largest crypto mining operations. Their existing tooling was a patchwork of vendor dashboards, spreadsheets, and manual SSH checks. Operators had no real-time view of individual miner health and no way to respond automatically when electricity prices spiked.
The business case was clear: if miners could automatically pause during high-price windows and resume when prices dropped, the energy savings would be substantial. But doing that reliably across 10,000+ devices, without missing a beat, required rethinking the entire infrastructure from the ground up.
- No unified visibility across 10,000+ devices spanning multiple data center locations
- Energy costs fixed, no mechanism to pause/resume miners based on real-time spot prices
- Zero automated failover when miners went offline, overheated, or fell below hashrate thresholds
- Manual processes meant operators spent 4–6 hours daily on health checks
- No audit trail for operational decisions or device configuration changes
Architecture: Event-Driven from the Ground Up
Every architectural decision was made with one constraint in mind: the system must never lose a command or a telemetry event. That led to a fundamentally event-driven design.
Direct HTTP polling of 10,000 devices was immediately ruled out, the latency, retry complexity, and server load would make it unworkable. Instead, each miner connects via MQTT, a protocol designed for constrained IoT devices with unreliable connections. Commands from the dashboard flow into RabbitMQ, which fans them out to the appropriate MQTT topics and guarantees delivery.
For metrics, PostgreSQL was the right choice for relational data (users, device configs, audit logs, NordPool schedules) but wrong for high-frequency miner telemetry. InfluxDB handled millions of time-series data points per day with efficient retention policies and fast aggregation queries for the real-time dashboard.
Redis served as the distributed state layer, every miner's live status (online/offline, temperature, hashrate, power draw) was cached with short TTLs, giving the UI sub-second reads without putting read pressure on the primary database.
Key technical decisions
Lightweight device protocol for telemetry; RabbitMQ for durable command queuing, fan-out, and guaranteed delivery to device groups. Reduced command latency from seconds to under 200ms.
PostgreSQL has poor performance for high-cardinality, high-frequency write workloads. InfluxDB gave us efficient per-device metric ingestion and fast aggregation for the dashboard charts.
Hot miner status data was cached in Redis with short TTLs. This decoupled the high-frequency write path (telemetry ingest) from the high-frequency read path (dashboard refresh) entirely.
A dedicated worker polls hourly spot prices and evaluates profitability per miner group. When a price threshold is crossed, it enqueues start/stop commands via RabbitMQ, no human in the loop required.
Outcome
The platform replaced a fragmented, manual workflow with a single real-time control plane. Operators went from spending hours on daily health checks to receiving targeted alerts and acting on exceptions only.
Need something similar?
I take on complex full stack projects, AI integration work, and data platform development.